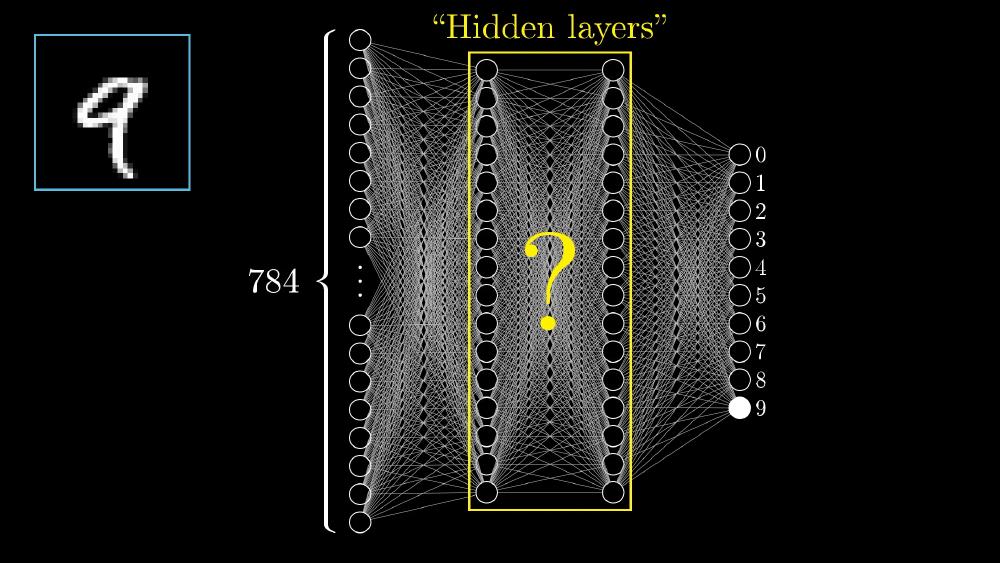
Chasing 99%: Analysis of my experiments...
This blog contains the full analysis of the models I trained on MNIST Dataset for digit recognition. Training set contains 60,000 images while test set contains 10,000 images.
You can follow along with the code in the repo Digit-Recognition-NN. I have written pretty detailed explanations in that jupyter notebook too about the choices and implementations.
A bit about implementation
I used $n$ Hidden Layer Fully connected Neural Network (not CNN because I don’t learn it yet :)).
Firstly the dataset is in idx3-ubyte (binary format). So i used struct library of python to read the binary file and extract the data into numpy array, then normalizing + zero centering the dataset to prevent erratic weight updates during training and help the optimizer to step quickly toward global minima.
Normalizing:
$$x_{train}=\frac{x_i - \bar{x}}{\sigma}$$Then use Dataloader module from pytorch to batch the training data into batch_size = 50. The reason is that without batching the optimizer updates weights based on loss for single image and hence a single noisy image can change the weights drastically. So we take a batch of particular size and then update weights based on average loss of full batch. And for that to work we also need to randomize the dataset first so that chances of a batch being filled by noisy images are low. For our MNIST dataset that part is already done by the researches who made it; so we are good to go!.
Models
My first architecture (2 Hidden Layer NN) contained 2 hidden layers apart from input and output layer:
- input layer of 784 neurons
- Hidden Layer
h1of 50 neurons - Hidden layer
h2of 50 neurons - output layer of 10 neurons as we have 10 classes [0,9]
| |
And as this is a C class classification problem, I used CrossEntropy as loss function as its standard for classification problems. It penalizes the model more when it is confident about an incorrect class; less if it is less confident. And implicitly the first neuron of output layer represents 0, 2nd neuron represents 1, and so on… because cross entropy function takes 0 indexed class indices. So it all perfectly aligns without any need for remapping of training labels data.
Also, used Adam optimizer to update weights based on gradient found by backpropogation using loss function.
Adam optimizer (Adaptive Moment Estimation) efficiently adjusts the learning rates during training (dynamic learning rate). It works well with large datasets and complex models as it efficiently uses memory and adapts the LR for each parameter automatically.
Tweaking with training parameters
Version 1, 2 and 3
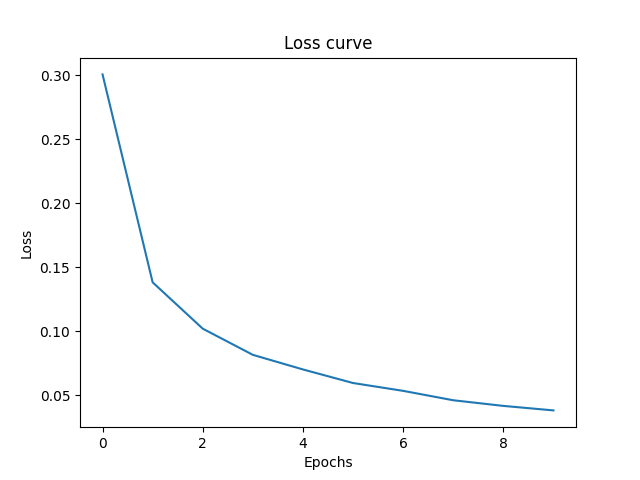
First I trained the model using 10 epochs, and accuracy was 97.24.
| |
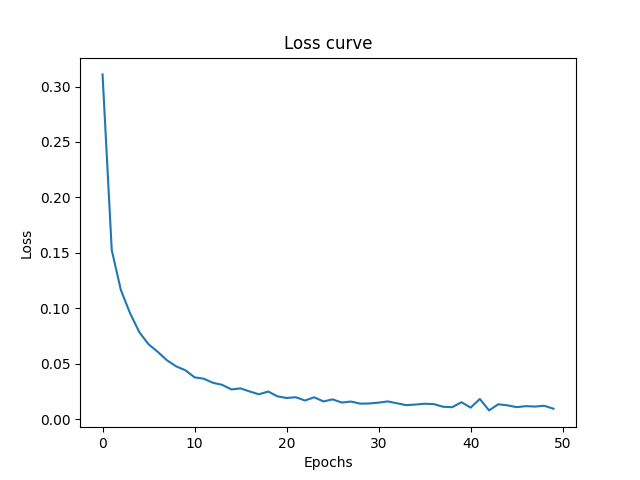
I then tried to increase the epochs to 50 to see the results:
| |
As you can see the SLIGHTLY performed better on both training and test dataset.
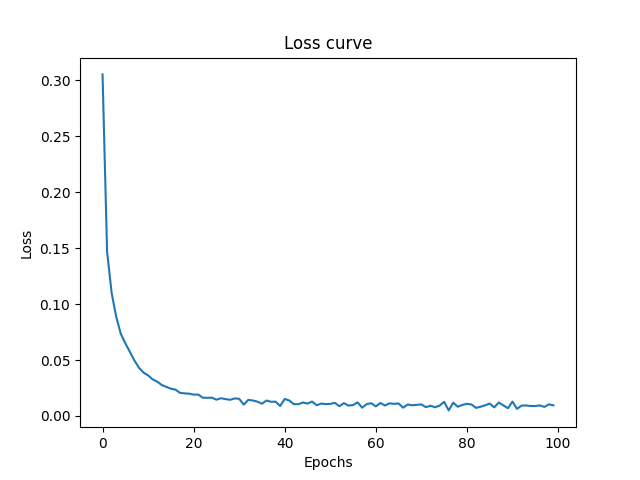
On 100 epochs the model performed substantially better
| |
If keep increasing that it starts overfitting and starts performing bad on the test dataset as we see later in the blog.
Loss Curves: As you can see more epochs gave the model more iterations to update its weights properly and hence the it navigates closer to global minima. The jaggy part of curve shows the points where model navigates to a uphill position due to momentum (learning rate) but in next iteration comes backs down the hill towards. Note that this is just simplification of N dimensional space onto 3 Dimensional for understanding.
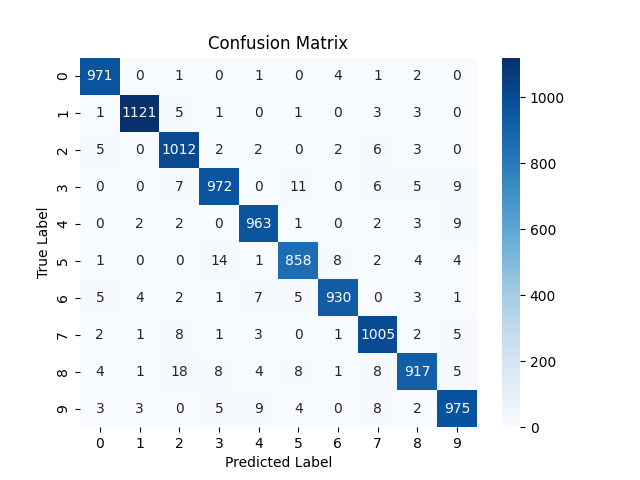
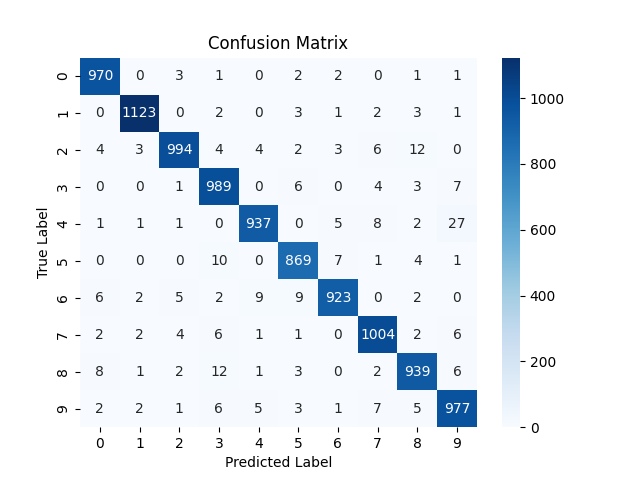
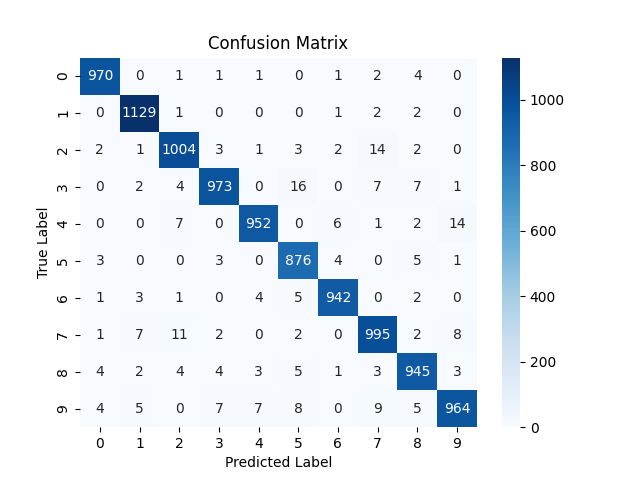
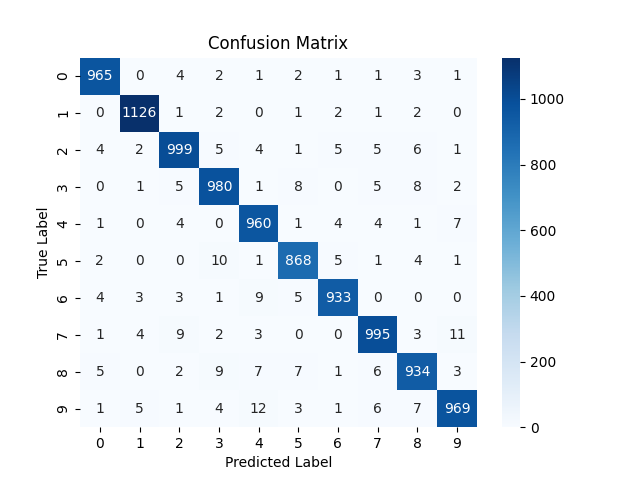
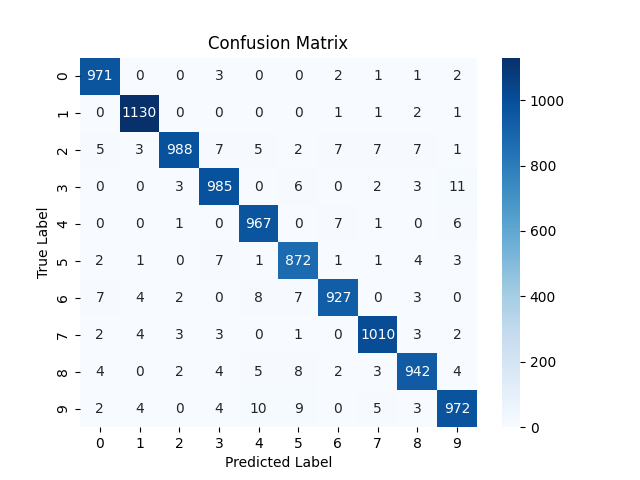
As you can see the model shows increase in positive classification rates (diagonals). Also there is decrease in confusion (wrong classification of some digits) although for some digits it increased a bit.
NOTE: the confusion matrix is based on the testing results on 10,000 test images.
Version 4
Now I increased the Learning Rate which means the optimizer will make more big steps, means more momentum. In some cases this helps because it can potentially move past a local minima due to momentum. But in some cases it may overshoot the global minima and prevents it from settling around minima due to momentum, where it constantly juggles back and forth on the valley and hill. In this case the accuracy decreased to 95% which means it failed to settle on the minima.
| |
Both training and test accuracy decreased.
Loss curve never settles, it is very “jaggy” due to reasons stated above.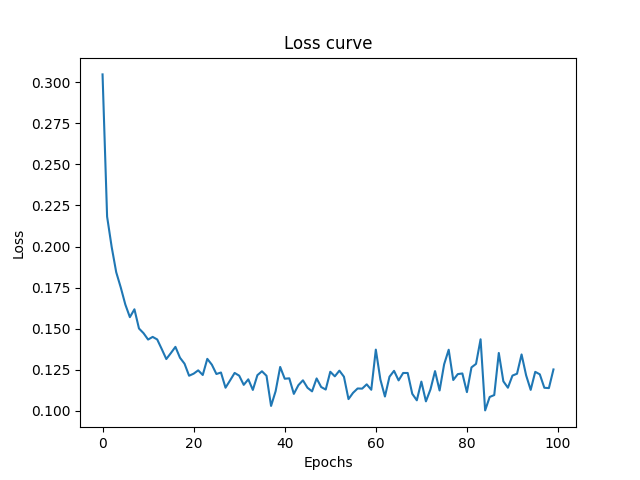
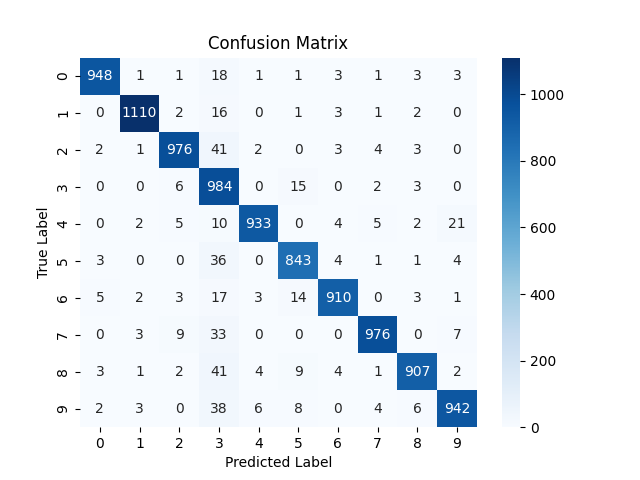
Confusion increased overall. One interesting observation is the column of digit 3. The model consistently predicted a number as 3 when it was not actually a 3. The possible reasons might be :
- 3 has much overlap in pixels to other digits. mainly the bottom right curve overlaps with 5,6,8,9,0 and top right curve overlaps with that of 2. So there is so much common area between 3 and other number. As LR was higher, the model failed to learn the fine differentiating factors that makes 3 a unique from all those. So whenever it sees that curves it default to 3.
- Or may be due to high LR, the model learned that whenever it is uncertain, the safest bet is to predict 3 to minimize loss.
Version 5
Now I decreased the learning rate to 0.0001, and now the train accuracy reached 100%, however compared to the 97.5% testing accuracy of model 2_HL_NN_v3 , this model had a bit lower testing accuracy, but the change is very small, so cant figure out the exact reason. Two possible reasons might be :
- overfitting on the training dataset. As it settled heavily on the minima of training landscape, it slightly learned less of logical relation, and just tried to fit to the training dataset.
- 2nd reason i think of is RANDOMNESS. Because the Neural Network is initialized randomly before training begins, there is always slight difference in output. I should have used
seedfor my network to be reproducible. But anyways I am fine with that :) as the changes is not substantial; only 0.06 percent decrease.
| |
However the learning curve was very SMOOTH as it should be due to small steps of optimizer.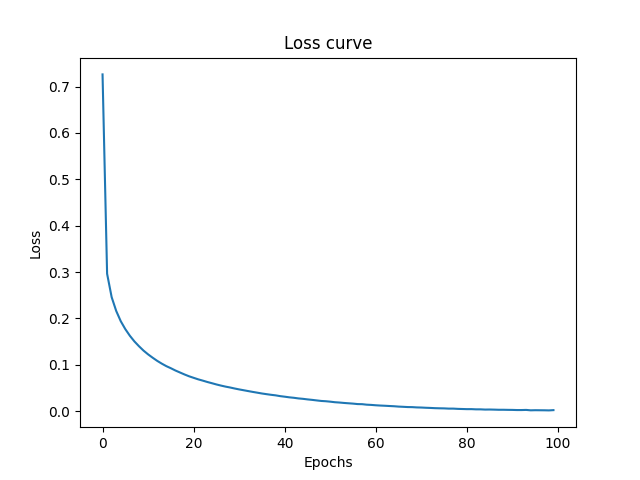
From now on I have kept the learning at 0.0001.
Version 6
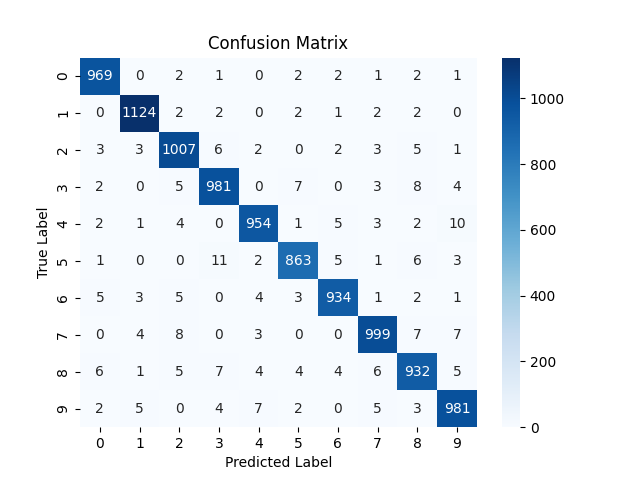
I increased the epoch to 500. And yeah it over fitted to training dataset. 100% train accuracy and 97.2% test accuracy. The test accuracy decreased a ton. The final train loss is much lower due to large iterations.
| |
Version 7
Now resetting the epoch to 50, I increased the batch size to 1000. And oops… the test and training accuracy came down to 95%!
| |
The possible reasons:
As you increased the batch_size the number of weight updates per epoch reduce from 1200 to just 60 weight updates. Now combine this with low learning rate of 0.0001 and total epochs of 50, the model didn’t get sufficient time to properly update the weights to descent to the global minima. (As both train and test accuracy decreased, this is the perfect reason. If only test accuracy decreased then it would mean overfitting.) The model did not converge properly in those 50 epochs.
Also large batch size strips away the noise inherent in the small batch size. Because of large size on average the noise gets minimized as there will be more perfect training images compared to noisy ones. That’s loss of regularization noise. Sometimes this noise helps optimizer in escaping sharp local minima that generalizes poorly.
Adam relies on the variance across batches to adapt the dynamic learning rates of neurons effectively. When the batch size is 1000, the gradients are so smoothed out that the variance between batches falls down. Adam’s adaptive mechanisms become much less effective, and it essentially behaves like standard gradient descent.
The most plausible reason I think is the first one. Actually when you increase the batch size, you should also increase the learning rate. This is the Linear Scaling Rule :
when multiplying the mini-batch size by a factor in deep learning, the learning rate should also be multiplied by to maintain stable training
You can read the Linear Scaling Rule in the paper Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour on [arxiv](https://arxiv.org/pdf/1706.02677#:~:text=Linear%20Scaling%20Rule%3A%20When%20the,other%20hyper%2Dparameters%20(weight%20decay%2C%20etc.)
Loss Curve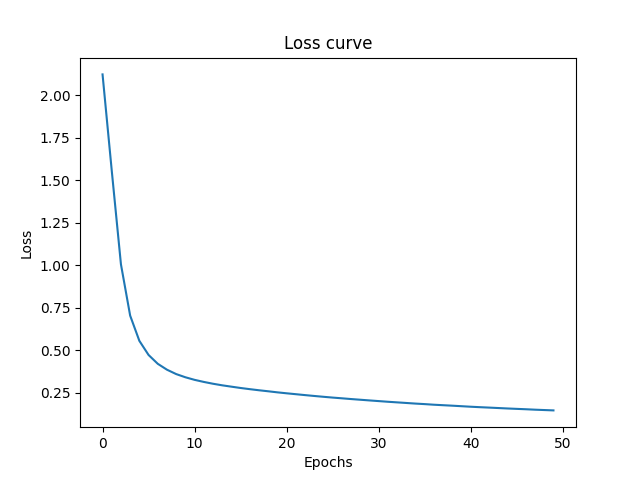
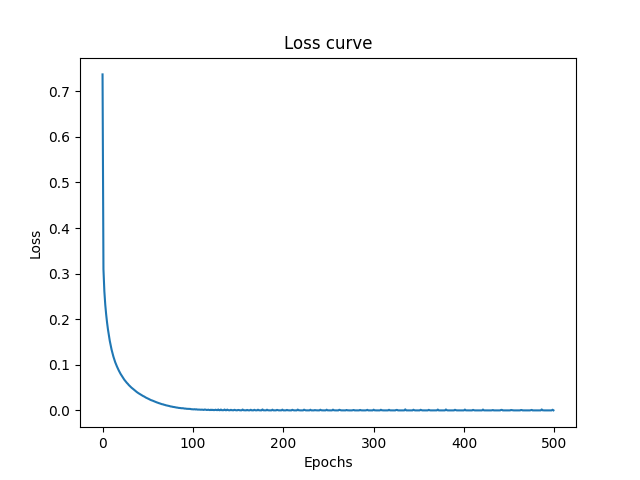
As you can see the curve had still not reached the plateau, when the training got finished.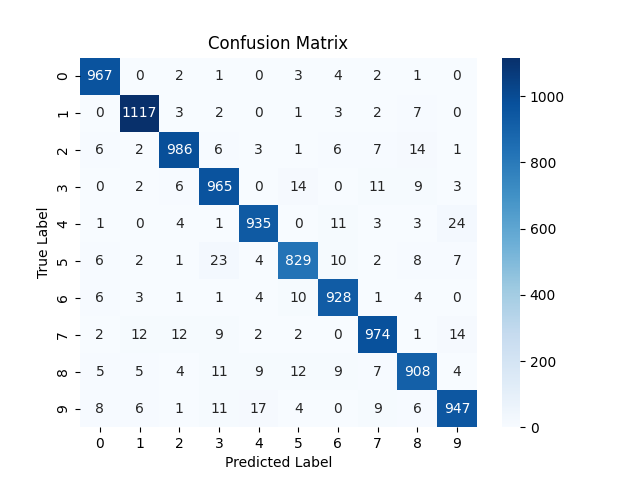
Version 8
Reduced batch size to 1. Which is essentially : no batching. Pure Stochastic gradient descent. And yeah this gave the highest testing accuracy of 97.64% (so far, we have better later).
| |
That’s because compared to batch size of 100 or 1000, it got exponentially higher number of weight updates 60000 weight updates per epoch; 3 Millions updates in full training . Its brute force! It got significantly more steps to traverse the loss landscape. This is also visible in terms of actual training time. It took around 50 minutes in total to train this model. which is so much longer then 5-10 minutes.; even though this dataset is relatively tiny compared to other datasets.
Did i use GPU then? Obviously yes, i used google colabs T4 GPU compute. But its of no use in this case, because batch size of 1 is essentially doing the training sequentially rather then using its full parallelization power. Its essentially like training on CPU or even worse if we take in account the setup overhead of GPU for computation like transferring of data from CPU VRAM to GPU’s VRAM, which in case of large batches gets spread over all samples, which compared to time advantage from parallelization makes it look tiny.
So for training models, batch size of 1 is terrible in most cases (if single batch does not need massive matrix multiplications).
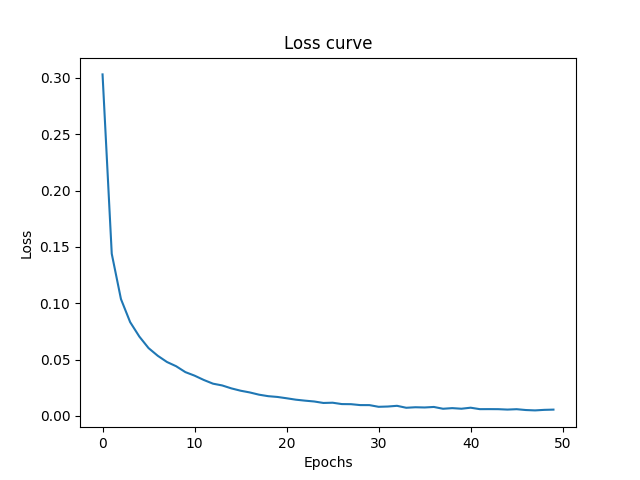
NOTE: MNIST dataset does not seem to be that noisy, otherwise the loss curve would have been very jaggy for batch size of 1 for the reasons already discussed above.
3 Hidden Layer NN
| |
Version 1
Got no substantial advantage.
| |
However the loss curve shows. As it didn’t reach the plateau at the end of training. However I retrained with 100 epochs but got no substantial increase.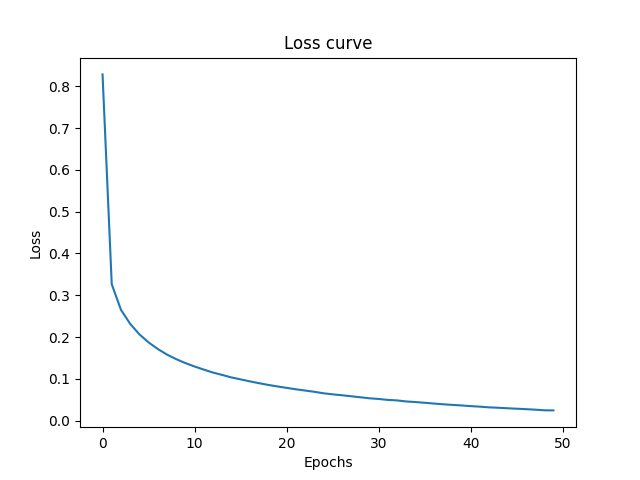
So it seems increasing the number of layers did none better than 2 layers. Hence it reminds us that “deeper is not always better” in deep learning. Especially for a simpler dataset like MNIST, stacking layers is not beneficial as such. The 2 Layer network is already capable of approximating a function to solve this problem; mapping a 784 dimensional vector to 10 dimensional vector. More layers are needed only when we have to approximate a much Complex Function like image classification on ImageNet dataset using CNN, with each layer learning some feature like texture, edges, etc.
In our case, adding more layers make the model learn very very fine grained pixel settings and noise which is not neccessary at all. The loss landscape becomes much more complex.
Even a single layer network gave fair results. 97.27% test accuracy and 99.97% train accuracy.
| |
Version 2
I tried to experiment with Sigmoid Activation function instead of ReLU. But as expected, it did worse.
| |
| |
The test accuracy decreased to 95.93%
Sigmoid Function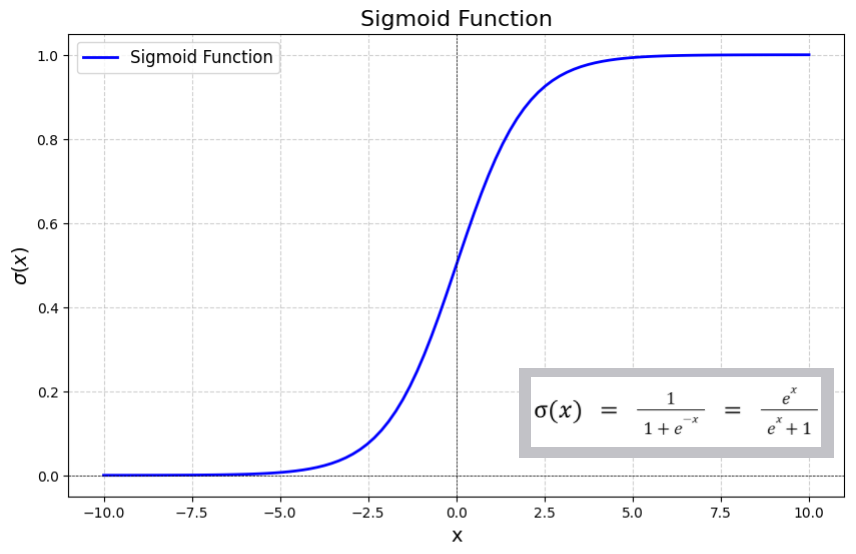
Most of the space accumulates around 1 and 0 and not in-between. And the gradient at that point tends to 0. And hence weights have less update magnitude. The derivative $\sigma'(z) = \sigma(z)(1 - \sigma(z))$, has an absolute maximum of $0.25$. In a 3 hidden layer architecture, the chain rule multiplies these fractions backward (e.g., $0.25^3 = 0.0156$ in the best case scenario), mathematically preventing the earliest layers of a meaningful learning signal.
Also if the neuron’s preactivation values are strongly positive or negative, the curve flattens completly making the gradient zero, and hence it FREEZES the neurons and restricts learning.
That’s commonly called Vanishing gradient problem.
To handle this usually we use two approaches:
Proper Weight Initialisation: Xavier Initialisation (Glorot Initialisation). It keeps the signal variance consistent across layers, preventing the weights from being so large or small that the sigmoid saturates (flattens out) at 0 or 1.
Input Scaling: Which we already did! Make input data normalised or standardised (typically scaled to a range like [0, 1] or [-1, 1]). If inputs are too large, the function immediately enters the flat regions where the gradient is nearly zero, effectively “killing” the neuron’s ability to learn.
ReLU Function: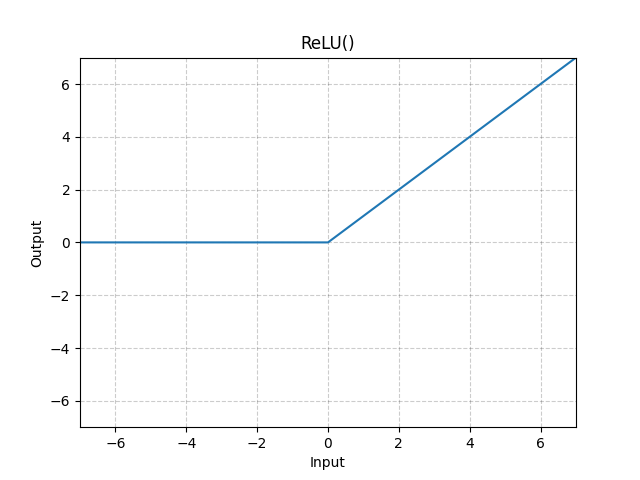
The learning signal does not diminish as it travels back to the earliest layers, completely eradicating the vanishing gradient problem that plagues sigmoid ($0.25 \times 0.25 \times 0.25$). Also there is no accumulation towards 1 on positive side, due to linear function.
However on negative side its complete 0. If a large gradient update pushes a neuron’s weights such that $z \le 0$ for the entire dataset, the neuron outputs 0, and gradient = 0. The weights can never update again. The neuron is mathematically dead.
In a deep network with a high learning rate, up to 40% of the ReLU network can silently die during early training, turning massive architecture into a highly constrained, inefficient model.
Version 3
Reducing number of neurons
| |
| |
The Test Accuracy decreased. Also observing the loss curve, its clear that the model has ample time for learning, as it started to reach a plateau around 0.2.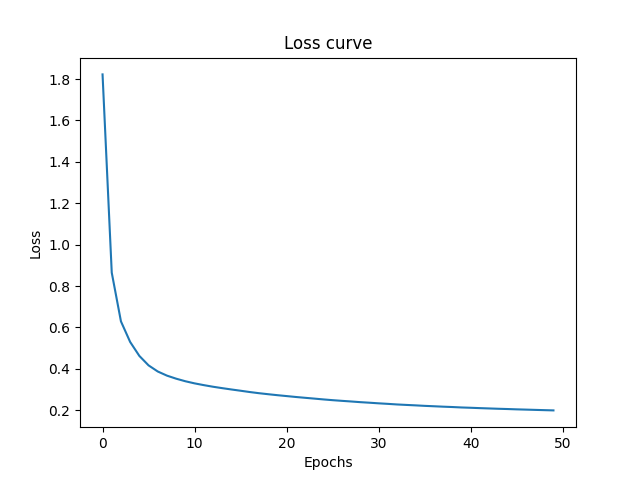
Its severe underfitting. So the issue is that less neurons failed to capture the nuances of the pixels 28x28 = 784. By mapping the input layer directly from 784 dimensions down to just 10we have a tight bottleneck for information.
The first hidden layer of a neural network is responsible for extracting low level features (like strokes or edges). To classify 10 distinct digits, the network needs to hold enough combinations of these strokes in its active memory. When we compress 784 pixels into a 10 dim vector, the projection matrix $W \in \mathbb{R}^{10 \times 784}$ forces the network to discard massive amounts of variance. This shows that it is mathematically impossible to linearly separate the complex, entangled features of the MNIST dataset within a space that is only 10 dimensions wide without losing critical distinguishing information.
Also the uniform number of neurons across layer posses a problem. Because the layers never expand, the network can never recover or recombine features into a higher-dimensional space to make them linearly separable before the final classification.
Version 4
Increasing neurons to 100. And yeah the accuracy increased to 97.81.
| |
| |
Version 5
Now increased the number of neurons to 1000 (more than 784 input dimensions), and yeah accuracy increased to 98.32%, the best model I got in this whole experiment.
| |
| |
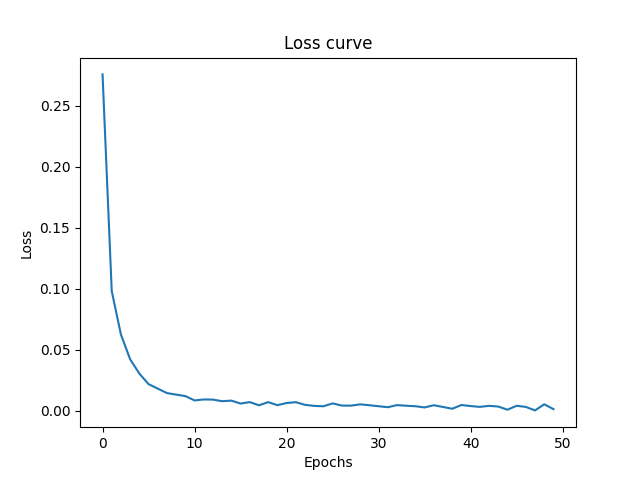
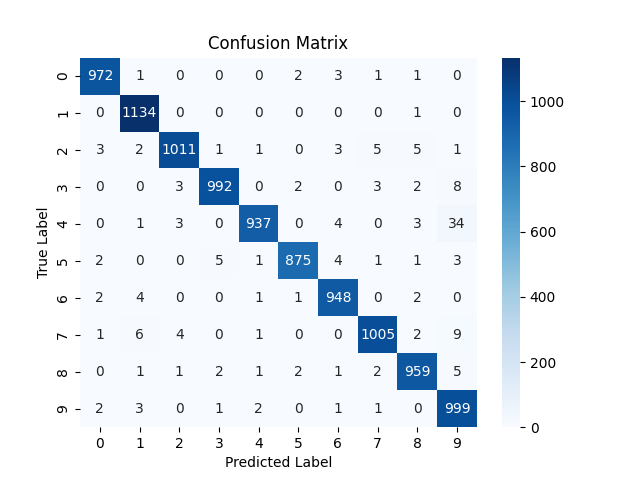
However there is unusually high confusion between 9 and 4 compared to previous models. These suggests the model successfully approximated the function for all other digits, except the 4 and 9. CNN would be help here.
The increase in accuracy may be due to it captured more detailed features and relation from that 784 pixels, to make a decision, but its not purely that actually. Also its slight overfitting if not more. Because as you increase the number of neurons, you give more space for model to just memorize the data. But the testing accuracy increased ANYWAY. This is likely the example of Benign Overfitting.
Benign overfitting is a phenomenon in machine learning where a model perfectly fits its training data (achieving zero training error), including any noise or random errors; yet still manages to generalize and perform with high accuracy on new, unseen data. This discovery challenges the “classical statistical wisdom” of the bias-variance tradeoff, which typically suggests that such extreme fitting leads to poor predictive performance.
Actually I never read about this before this experiments. I just increased the number of neurons to see the results out of my curiosity and found it unusual that the test error to training error actualy decreased instead of overfitting and then went on to do some research on the topic. But as it came to be : its already published :( sad life.
This actually is a highly active and “hot” field in deep learning theory, as it provides the theoretical backbone for why modern overparameterized models; like LLMs; work so well. This behavior is the exact setup that gave birth to the Modern Deep Learning Theory.
It is hot in the sense that earlier work was focused only on Linear regression or simple kernels and not Neural Networks like this. It is just that recent high-impact papers (2024–2025) are finally bridging the gap to deep ReLU networks and non-linear settings.
The core idea is that in highly complex, over-parameterized models (like deep neural networks), the model’s prediction rule can be split into two parts:
A Simple Component: A low-complexity part that captures the actual underlying signal or pattern in the data.
A “Spiky” Component: A high-complexity part that “absorbs” the noise at specific training points without affecting the model’s overall shape or predictions elsewhere. arXiv
It generalized despite of overfitting.
Actually we can plot a curve of number of neurons and test errors. Which would show the phenomenon of Double Descent which was studied by Mikhail Belkin in 2018 and then in 2019 by OpenAI researches as Deep Double Descent
Double descent is a machine learning phenomenon where a model’s test error first decreases, then increases, and finally decreases again as model complexity or training time grows.
Deep Double descent (OpenAI) - they extended it to Deep and complex neural networks beyond normal ML models just like I did in my case for MNIST dataset. OpenAI did it for ResNet18.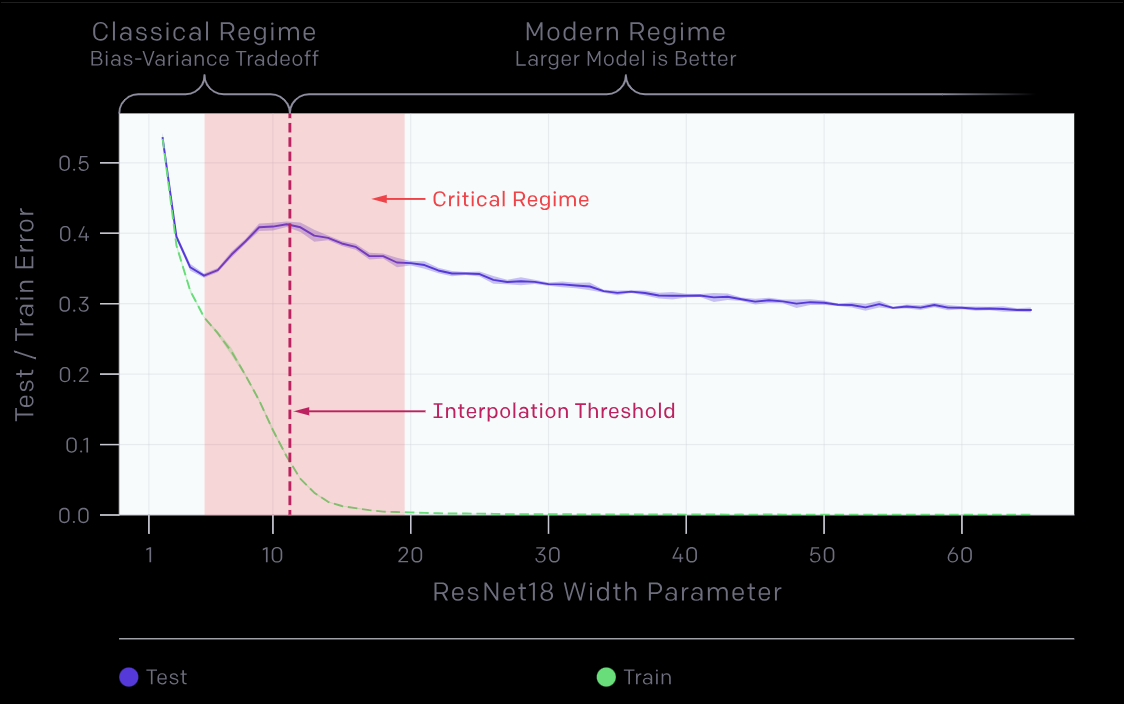
Also this network surely has many redundant neurons.
NOTE: This model took 34 minutes to train due to high number of neurons. So brute forcing didn’t gave significant returns : Exponential increase in number of neurons gave decaying returns.
100 neurons : 97.8 1000 neurons: 98.32
Let’s see what CNN can achieve compared to these soon.
Discussion
What are your thoughts on this? Leave a comment below.